
News
TSMC Kumamoto: Pioneering Japan’s Semiconductor Revival
TSMC’s Kumamoto facility, operationalized through Japan Advanced Semiconductor Manufacturing (JASM), marks a strategic diversification of its global manufacturing footprint, being its first dedicated wafer fab outside Taiwan, the U.S., and Europe. The facility focuses on mature process nodes (22/28nm and 12/16nm) crucial for automotive semiconductors, image sensors, and microcontrollers.

- TSMC’s strategic pivot with its Kumamoto fab diversifies manufacturing globally, bolstering supply chain resilience.
- The facility focuses on mature nodes, leveraging renewable energy and creating 2,400 jobs, to support key sectors like automotive and image sensors.
- Kumamoto significantly contributes to Japan’s “Semiconductor Revival Plan,” aiming to reclaim a share of global chip production, despite some infrastructure challenges for future expansions.
Launches
Silicon Photonic Interconnected Chiplets With Computational Network And IMC For LLM Inference Acceleration
Researchers at the National University of Singapore have unveiled PICNIC, a 3D-stacked chiplet-based large language model (LLM) inference accelerator. PICNIC tackles critical communication bottlenecks by employing silicon photonic interconnections and non-volatile in-memory computing processing elements. This innovative architecture significantly enhances speed and efficiency for LLM inference.

- PICNIC is a novel 3D-stacked chiplet accelerator leveraging silicon photonics for efficient LLM inference.
- It integrates an Inter-PE Computational Network and in-memory computing to overcome communication bottlenecks in LLM processing.
- Simulation results indicate a substantial 3.95x speedup and 30x efficiency improvement over the Nvidia A100, with further scalability to rival the H100.
Charts
Lessons from the DeepChip Wars: What a Decade-old Debate Teaches Us About Tech Evolution
A review of hardware-assisted verification (HAV) trends over the last decade reveals a dramatic evolution driven by soaring design complexity, embedded software growth, and the rise of AI workloads. Key shifts include a reversal of priorities from compile time to runtime performance, a move from multi-user parallelism to single, system-critical validation runs, and a transformation in debugging from waveform visibility to system-level insights. This evolution is summarized in a table showcasing the changing attributes of HAV systems.
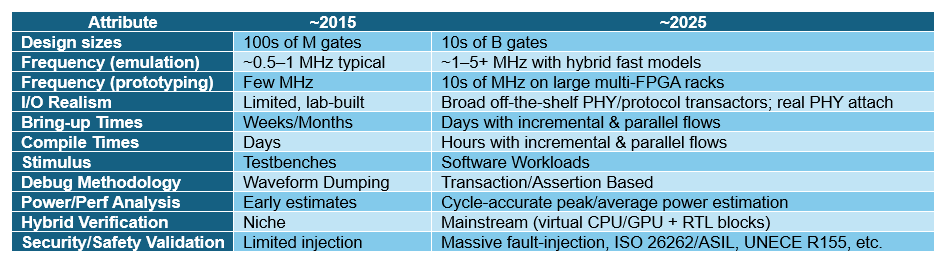
- HAV priorities have shifted dramatically, favoring long runtime performance for complex software workloads over rapid compile times.
- The focus of capacity utilization transitioned from running many small jobs in parallel to executing single, system-critical validation runs for massive, multi-die architectures.
- Debugging techniques evolved from low-level waveform visibility to high-abstraction system-level analysis, utilizing software debuggers and protocol analyzers.
Research
Algorithm–HW Co-Design Framework for Accelerating Attention in Large-Context Scenarios
Cornell University researchers have introduced LongSight, an innovative algorithm-hardware co-design framework to accelerate the attention mechanism in large-context LLMs. LongSight utilizes a compute-enabled CXL memory device to offload the Key-Value (KV) cache storage and retrieval, effectively enabling state-of-the-art Llama models to support context lengths of up to 1 million tokens. This approach elevates the value of relatively low-cost LPDDR DRAM to that of high-end HBM.

- LongSight accelerates large-context LLMs by offloading the critical KV cache to compute-enabled CXL memory.
- This framework allows LLMs to efficiently support context windows of up to 1 million tokens, enhancing output accuracy and personalization.
- It effectively leverages lower-cost LPDDR DRAM to function at high-end HBM capacities for LLM acceleration.
Insight
Adding Expertise to GenAI: An Insightful Study on Fine-tuning
An insightful analysis of a Microsoft study explores methods for fine-tuning pre-trained Generative AI models (like GPT-4) to embed specific expertise, such as knowledge of recent sporting events. The study compares token-based and fact-based approaches to supervised fine-tuning (SFT), concluding that fact-based training, which breaks down complex sentences into atomic facts, yields more uniform coverage and significantly improved accuracy. The article emphasizes the dynamic nature of fine-tuning, the critical role of expert review, and the ongoing challenge of achieving 100% model accuracy while mitigating issues like catastrophic forgetting.

- Fine-tuning GenAI models is crucial for embedding specific expertise and significantly enhancing response accuracy over base pre-trained models.
- Fact-based fine-tuning, by breaking down complex sentences into individual labels, demonstrates superior and more uniform coverage compared to token-based methods.
- Expert human review and careful label generation are vital for building confidence in enhanced models and preventing issues like “catastrophic forgetting.”
Stay tuned for the latest updates shaping the semiconductor landscape!